Text Conditioned Auxiliary Classifier Generative Adversarial Network, (TAC-GAN) is a text to image Generative Adversarial Network (GAN) for synthesizing images from their text descriptions. TAC-GAN builds upon the AC-GAN by conditioning the generated images on a text description instead of on a class label. In the presented TAC-GAN model, the input vector of the Generative network is built based on a noise vector and another vector containing an embedded representation of the textual description. While the Discriminator is similar to that of the AC-GAN, it is also augmented to receive the text information as input before performing its classification.
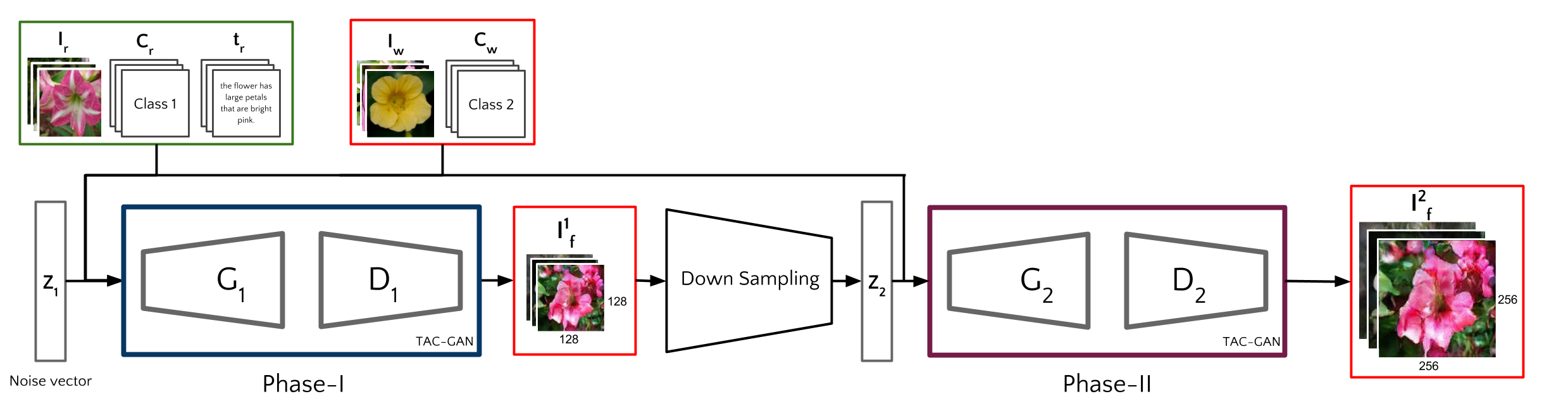
The following image shows the architecture of TAC-GAN
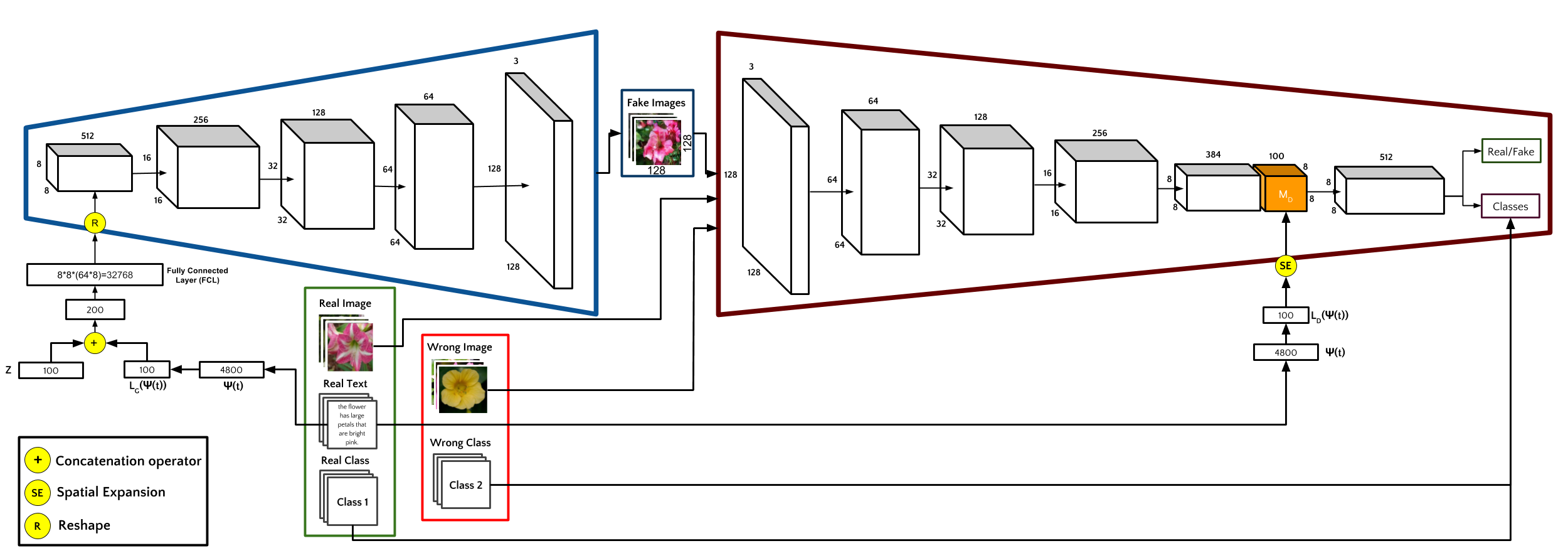
In the Architecture diagram, t is a text description of an image, z is a noise vector of size N_z, I_real and I_wrong are the real and wrong images respectively, I_fake is the image synthesized by the generator network G, Ψ(t) is the text embedding for the text t of size N_t, and C_r and C_w are one-hot encoded class labels of the I_real and I_wrong, respectively. L_G and L_D are two neural networks that generate latent representations of size N_l each, for the text embedding Ψ(t). D_S and D_C are the probability distribution that the Discriminator outputs over the sources (real/fake) and the classes respectively.
While brainstorming with the members of MindGarage we came up with an idea to incorporate indirect information into a Generative Adversarial Network. We thought it might be a great idea to implement a Text to Image Generative model and augment the class information without conditioning the Generator on the Class Label. My close friend John and I sat down, did the maths and realised that it seems to make sense. To be very honest, understanding the Maths of Generative Adversarial Networks was not an easy task :-P We had to download the latex source of the paper and went through the commented sections (which I believe everyone who is trying to understand the proofs in the GAN paper should go through). I would even recommend people who want to understand the maths behind such Generative models in depth, to go through On Unifying Deep Generative Models. It is quite maths intensive. But, I think this article will give you a bigger picture of how the deep Generative Models work.
John and I ended up brainstorming almost every other week and finally realised that our work is actually very simple. We were surprised that no one had explicited it earlier. We even Had the idea of using Self Attention in the Generator network but it seemed to not work (because of a very small mistake in my code that I realised later). We were trying to attend to the text embeddings at every layer of the Generator Network.



Evaluating generative models, like GANs, have always been a challenge. While no standard evaluation metric exists, recent works have introduced a lot of new metrics. However, not all of these metrics are useful for evaluating GANs. Salimans et al. proposed that inception score can be considered as a good evaluation metric for GANs to show the discriminability of the generated images. Odena et al. have shown that Multi-Scale Structural Similarity (MS-SSIM) can be used to measure the diversity of the generated images.
Our approach outperforms the state-of-the-art models, i.e., its inception score is $3.45$, corresponding to a relative increase of $7.8\%$ compared to the recently introduced StackGan. A comparison of the mean MS-SSIM scores of the training and generated samples per class shows that our approach is able to generate highly diverse images with an average MS-SSIM of $0.14$ over all generated classes.
We described the TAC-GAN, a model capable of generating images based on textual descriptions. The results produced by our approach are slightly better to those of other state of the art approaches.
The model is easily extensible: it is possible to condition the networks not only on text, but in any other type of potentially useful information. It remains to be examined what influence the usage of other types of information might have in the stability of training, and how much they help, as opposed to hinder, the capacity of the model in producing better quality, higher resolution images.
Many approaches have used a multi-staged architecture, where images produced in the first phase are iteratively refined in subsequent phases. We believe that the results of our model can benefit from such a pipeline, and be able to further improve the results reported in this work.