

Machine Learning basics: A basic understanding should be enough.
Solving a real world problem using machine learning is not so trivial. If done haphazardly, it may lead to a disaster or waste of a lot of effort. I have seen people directly jumping into choosing a classification algorithm for solving a pattern recognition task and ending up with an accuracy of 20%. Problem solving does not mean selecting an algorithm to solve a problem. It needs proper analysis and understanding of the problem itself. So, my dear friends, for making sure that you do not end up banging your head on the wall saying “I wasted a lot of time for nothing” we have The Pipeline. This might sound a little boring and is a ”Not So Fun” part of Machine Learning, but believe me, it is highly necessary for getting better results. Remember the bigger picture that I had talked about? If not then read this.
What kind of problem are you trying to solve?: ask this question to yourself before jumping into anything. The following are a few examples,
Classification Problem : Where you want to classify data into different classes.
Regression Problem : Where you want to predict some results given some observations.
Feature Extraction: Extracting features from a given dataset that best represents your data.
Information Retrieval: Where you have a set of documents and you want to retrieve the most relevant documents given a search query.
And much more…
Can the problem be divided? : After classifying the problem, determine whether you can divide the problem into subproblems or not. If you can, then do the same for every subproblem too.
How does the environment look like? : By environment, I mean the environment of your system. The following are a few questions that you can ask yourself to understand the environment better,
Is the data accessible to the system?
Is the data that the system gets continuous or discrete?
How static or dynamic is your data.
Is your data continuous or discrete?
For details about environments from an Artificial Intelligence point of view, read this.
For example, If my problem is “Recognising sign language using Myo armband and converting that into speech” then
The problem is a Classification Problem as I want to classify different hand gestures into a set of signs in a sign language.
The Environment is,
Accessible : Time series data from EMG Pods, accelerometer and gyroscope of the Myo Armband.
Dynamic: The data from the sensors change dynamically.
Continuous : The data is time series, which means that we end up getting a sequence of data samples over time.
And partially observable : Not everything is accessible from these sensors like fine finger movements.
Once you have classified your problem and environment, you can follow a two-step process to obtain the best model for your system.
This is just an analysis step that will help in better understanding your data and later will help us in determining which Machine Learning Algorithm you should use.
Collect sample data from the environment for analysis. DO NOT collect all the data now. You just need a few samples for analysis.
Visualise the data to understand how it looks like and how it is distributed.
Try to find out unique characteristics in your data. These characteristics can be features or combination of features.
Determine what and how much preprocessing is required to clean and normalise the data.
Determine if you can have labelled data for training, in the case of a classification problem.
Think of algorithms that can help in getting the desired result given such a data.
Depending on whether you can have labelled or unlabeled data for training, you can decide whether you would use a supervised or an unsupervised learning algorithm. For more details read this. Continuing the example of converting sign language to speech, the following are two different visualisations of the time series data that was acquired from the Myo Armband.
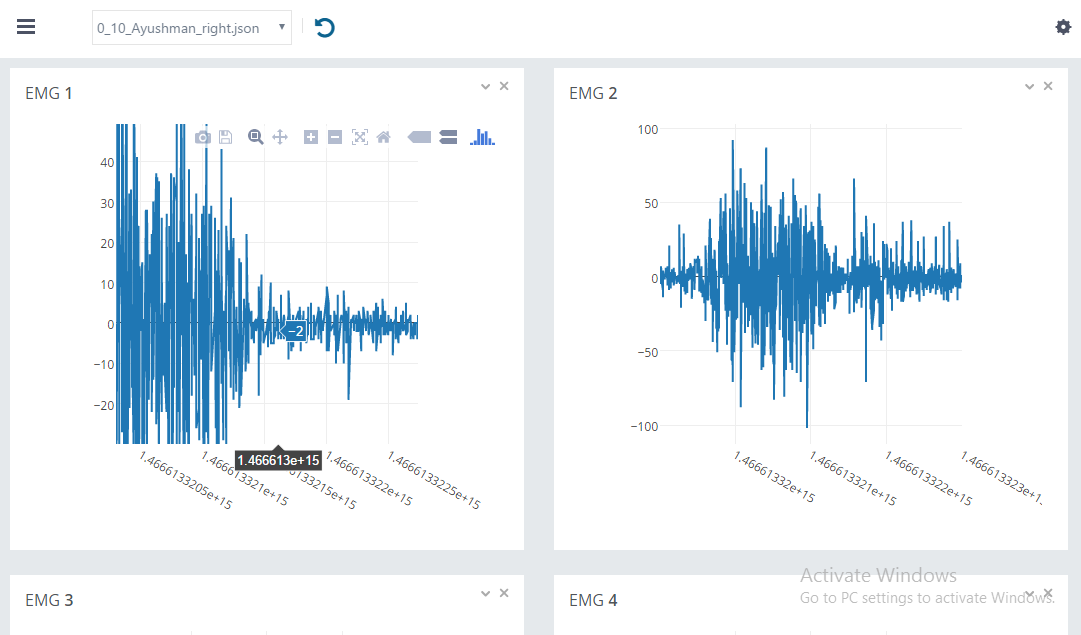
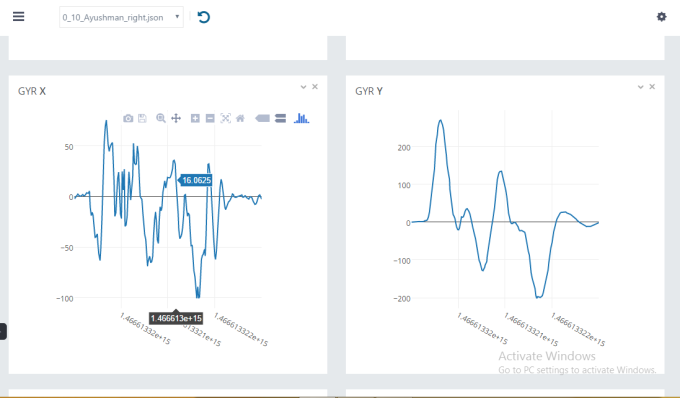
By following Step 1 we could,
Understand the difference between the data from two different users.
Think of normalisation and scaling techniques for preprocessing the data.
Think of a set of features that we could extract from the data.
Distinguish variant and invariant features.
Realise that we could collect labelled data by conducting experiments.
Think of Machine Learning Algorithms that might work in our case.
HMM (Hidden Markov Models)
SVM (Support Vector Machine)
LSTM Networks (Long Short Term Memory Networks)
Data Acquisition : Acquire the training data
Data Preprocessing : The following are a few examples of preprocessing,
Scaling: Scaling the data is highly necessary for standardising the model. In the next post, I will explain feature scaling with an example.
Normalisation: normalising the data by resampling or filtering
Feature Extraction : Extract features from the data that represent your data well.
Feature Scaling: If you intend to use Maximum likelihood estimation for parameter estimation or optimisation algorithm like Gradient Descent for optimising your parameters then scaling the features is highly necessary so that you arrive at the best parameters faster. Dr Andrew Ang has explained it in a very subtle way here.
Model Generation : Use any machine learning algorithm (Supervised or Unsupervised) to generate a model for your system.
Evaluation : Evaluate your model using k-fold-cross-validation (There are many other but this works the best for me. So, keep experimenting) and a few standard evaluation metrics like,
Precision
Recall
Contingency Matrix
Anova
ROC
F-Measure
I will continue our example of converting sign language to speech for step-1 and 2 in my upcoming posts. Do not get overwhelmed by the terms that you have read above. I will cover everything in step 1 and 2 in detail one by one.
The answer is pretty simple. To assure that we have a highly optimal model at the end for solving our problem.
This was my research project and it extensively covers every step in the entire machine learning pipeline . I learnt a lot from this project and I think it can help you folks in understanding a real-world problem and how Machine Learning can be used to solve it. Plus I think that it is a really cool application of Machine Learning.
In my upcoming posts, I will break the example down as mentioned above and show the challenges that you might face and how to solve them. So if you have a few questions then I would ask you to be patient and go through the links for getting a better understanding. I will cover every point of step-1 and step-2 in detail in individual posts so that you get a clear idea about how things work in the Machine Learning world.